从源码角度分析Spring循环依赖
本文从源码的角度分析 Spring 是怎么样解决循环依赖的,我想你肯定会回答三级缓存,但是为什么是三级缓存,而不是二级缓存了?三级缓存分别解决了什么问题?三级缓存是万能银弹吗?是否能解决所有的循环依赖?
循环依赖的常见三种类型
属性依赖注入循环依赖
@Component
public class BeanA {
@Autowired
private BeanB beanB;
}
@Component
public class BeanB {
@Autowired
private BeanA beanA;
}对于这种属性依赖注入而产生的循环依赖 Spring 可以通过三级缓存去帮我们解决,但是前提条件是有一方必须是单例的,如果循环依赖的两方都是原型的话,单纯依靠 Spring 的三级缓存是无法解决循环依赖的。可以考虑将一方的依赖使用 @Lazy 注解来打破循环依赖。
构造函数依赖注入循环依赖
@Component
public class BeanA {
private BeanB beanB;
@Autowired
public BeanA(BeanB beanB) {
this.beanB = beanB;
}
}
@Component
public class BeanB {
private BeanA beanA;
@Autowired
public BeanB(BeanA beanA) {
this.beanA = beanA;
}
}而对于构造函数依赖注入而产生的循环依赖,Spring 也无力回天,因为这是一个先有鸡还是先有蛋的两难,要解决这种因构造函数依赖注入而产生的循环依赖,就需要打破这种两难,必须决策出到底是先有鸡还是先有蛋。
使用 ObjectFactory 解决构造循环依赖
@FunctionalInterface
public interface org.springframework.beans.factory.ObjectFactory<T> {
T getObject() throws BeansException;
}ObjectFactory 是 Spring 提供的一个函数式接口
@Component
public class BeanB {
private ObjectFactory<BeanA> beanA;
@Autowired
public BeanB(ObjectFactory<BeanA> beanA) {
this.beanA = beanA;
}
}使用 ObjectFactory<T> 包装你的依赖,即让一方先完成它的创建,延迟了你的依赖,当你第一次去调用 getObject 方法时才会创建 BeanA 返回给你。
使用 @Lazy 注解解决构造循环依赖
@Component
public class BeanB {
private BeanA beanA;
@Autowired
public BeanB(@Lazy BeanA beanA) {
this.beanA = beanA;
}
}使用 Lazy 注解其实就是先创建一个 BeanA 的代理对象给你,让你先满足你需求完成你的创建,当你创建完毕以后,那么鸡就先有了,循环依赖就被打破了。
@DependsOn 注解引发的循环依赖
@Component
@DependsOn({"beanA"})
public class BeanB {
}
@Component
@DependsOn({"beanB"})
public class BeanA {
}对于这种循环依赖,Spring 是无法解决的,所以我们编码的时候应该避免出现这种情况。
推演解决循环依赖
循环依赖是怎么产生的?
图一
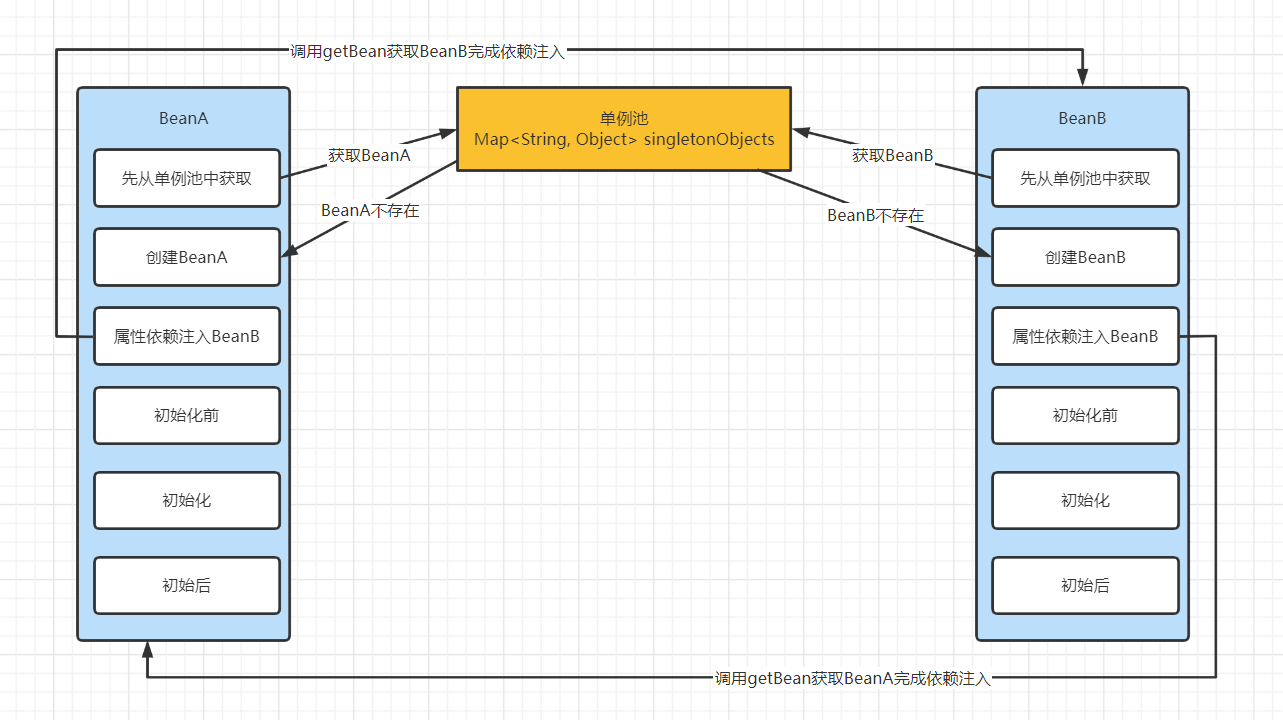
在上面的图中,有两个单例 Bean,分别是 BeanA 和 BeanB,我们都知道我们从容器中获取 Bean 都是需要通过 getBean 方法去获取 Bean 对象的。假设我先调用 getBean 获取 BeanA,因为我们的单例 Bean 实例实际都是缓存在一个 singletonObjects 的 Map 集合里面,那么先会尝试去单例池中获取 BeanA ,此时肯定单例池中肯定没有,所以会通过构造函数去创建 BeanA,创建完 BeanA 对象后,会寻找 BeanA 的 注入点为其注入属性,此时我们又会调用 getBean 方法去获取 BeanB 来完成对 BeanA 对象的 BeanB 属性注入值,那么我们的程序就会走到创建 BeanB 的流程,但为 BeanB 寻找注入点的时候发现有需要注入 BeanA,又转头去创建 BeanA 对象,此时就发生了一个死循环,形成了一个闭环。
如何打破循环?
图二
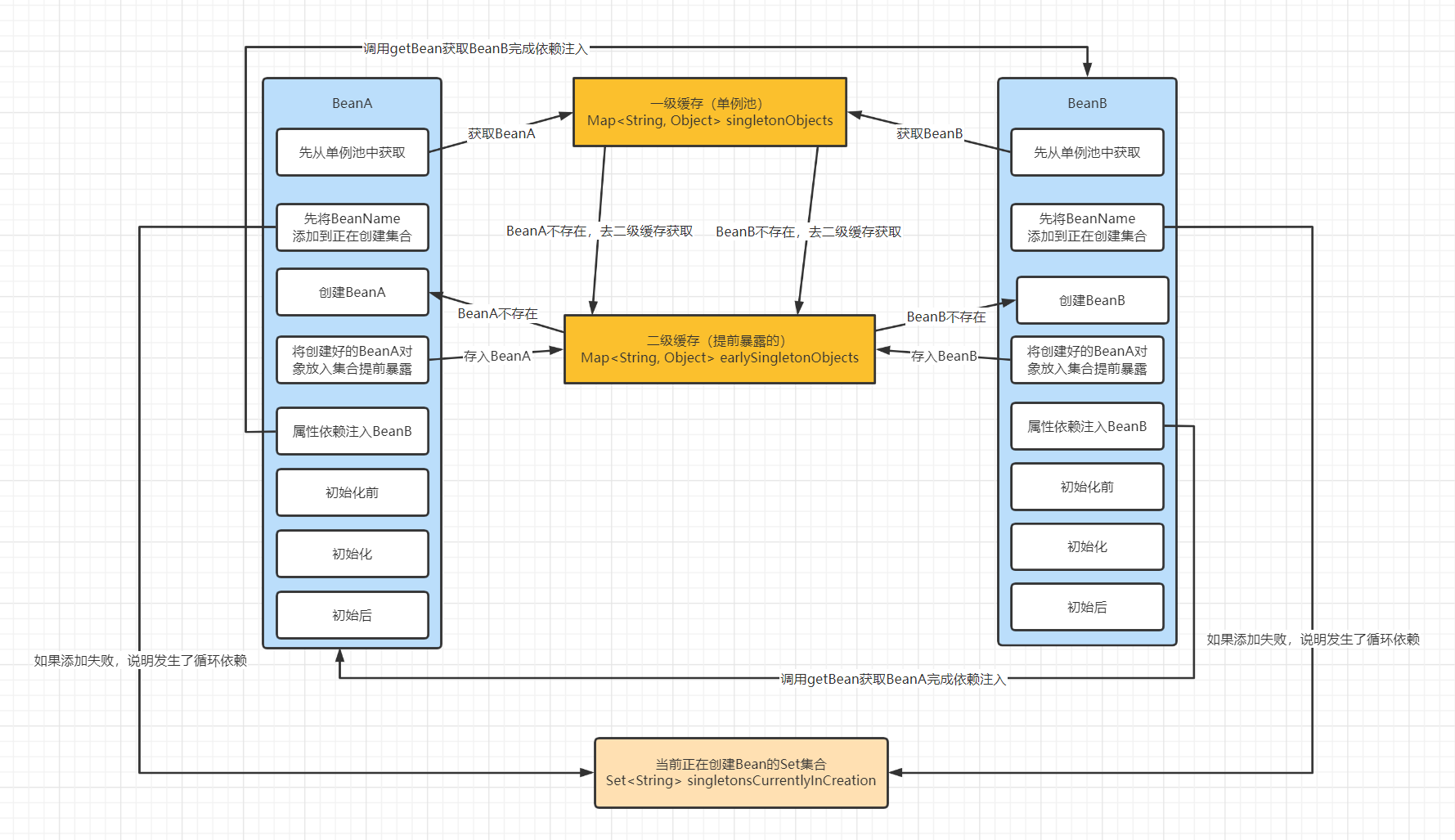
经过图一的分析,发现了一些问题,比方说我们无法感知到程序发生了循环依赖,从而产生了死循环,这显然不是我们期望的,我们可以在创建 Bean 之前做一些检查动作。把当前要创建的 Bean 标记一下,添加到一个 Set 集合里面,标识这个 Bean 正在被创建中,如果第二次再来创建这个 Bean 时,因为你已经添加过一次了,会添加失败,说明此时就发生了循环依赖,我们就可以把这个问题抛出去交给调用者解决。另外一个问题,可以在创建完 BeanA 就把 BeanA 对象放在一个二级缓存中(为什么不直接放入一级缓存中了?因为一级缓存中都是存放的是已经执行完所有生命周期流程的 Bean 实例),然后继续执行下面的流程,那么等到去创建 BeanB 的时候,BeanB 是可以在二级缓存中找到它所依赖的 BeanA 对象完成依赖注入。到这里好像一切都很完美,似乎只需要二级缓存就能解决循环依赖的问题,但真的是这样吗?
AOP 对象不一致
我们都知道 Spring 的 AOP 是在依赖注入后才进行的,假设 BeanA 需要 AOP,那么就会产生一个代理对象,而 BeanB 在二级缓存所拿到的 BeanA 对象是原始对象,不是经过 AOP 的代理对象,那么这肯定不是我们所期望的,此时我们就需要引入第三级缓存来解决这个问题。
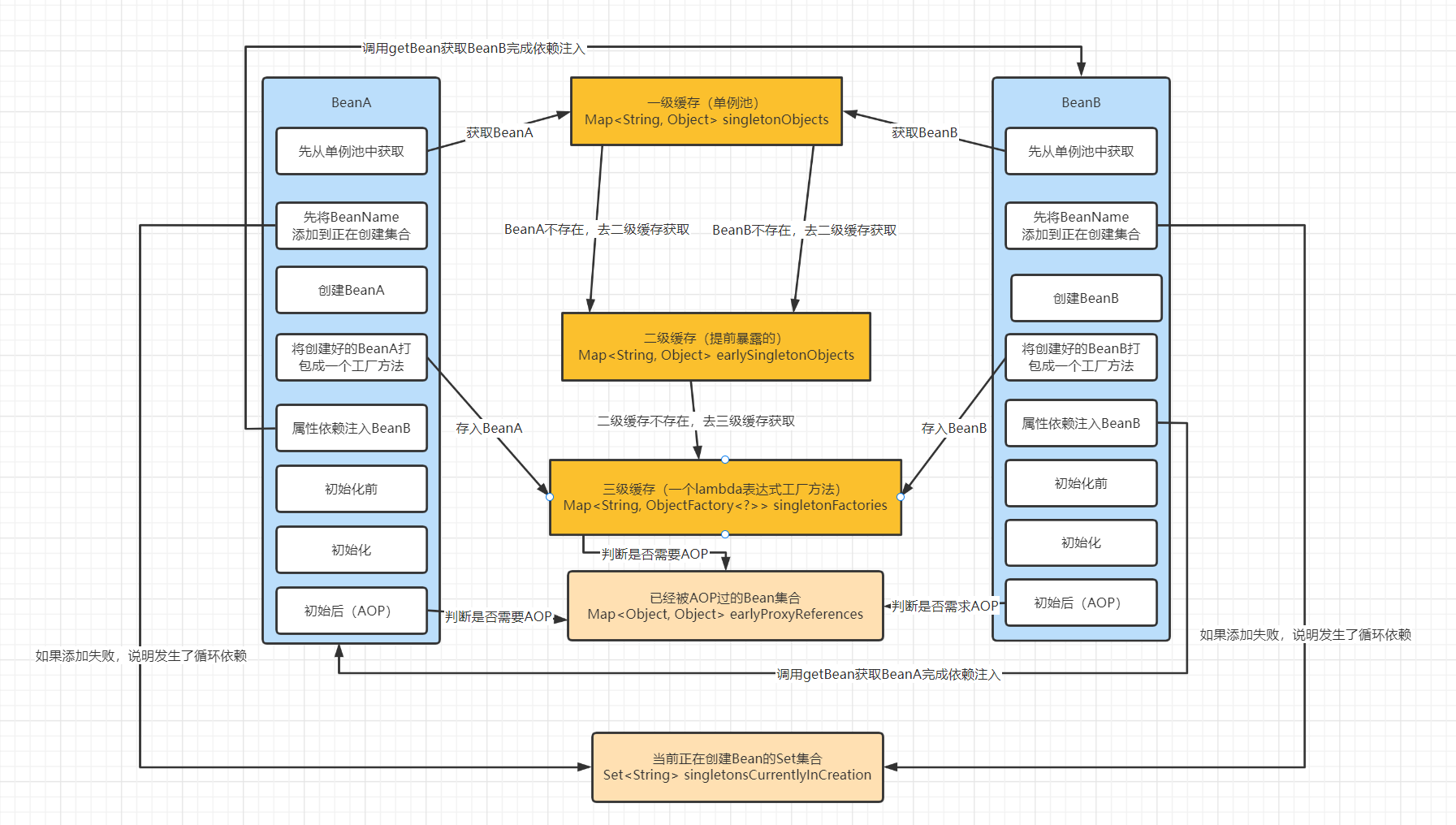
三级缓存存放的是一个 lambda 表达式,里面有一个逻辑就是判断你这个 Bean 是否需要 AOP 如果需要的话,会在这个表达式里面 AOP 然后将代理对象返回给你,即提前进行 AOP,如果不需要 AOP 的话,直接返回原始对象即可。但是假设我们已经在三级缓存获取 BeanA 表达式执行,并生成了代理对象,那么对于 BeanA 自己来说它是肯定不能再次 AOP 的,不然产生了两个 BeanA 的代理对象,所以所有 AOP 过的代理对象都需要一个集合存放着来标记这个 Bean 已经经过了 AOP。
从源码看 Spring 的三级缓存实现
程序的入口
下面的源码分析都是基于 Spring 5.3.10 版本的,版本差异代码实现可能会有所不同。在 Spring 中不管是创建 Bean 还是 获取 Bean 都是从 getBean 开始,getBean 的实现会帮你去寻找你需要的 Bean,如果找不到就会去创建,当然前提是你得有这个 Bean。在 BeanFactory 接口的几个 getBean 的重载方法都是调用了 AbstractBeanFactory 这个类的 doGetBean 方法去实现的。
@Override
public Object getBean(String name) throws BeansException {
return doGetBean(name, null, null, false);
}
@Override
public <T> T getBean(String name, Class<T> requiredType) throws BeansException {
return doGetBean(name, requiredType, null, false);
}
@Override
public Object getBean(String name, Object... args) throws BeansException {
return doGetBean(name, null, args, false);
}
public <T> T getBean(String name, @Nullable Class<T> requiredType, @Nullable Object... args)
throws BeansException {
return doGetBean(name, requiredType, args, false);
}doGetBean 解析
protected <T> T doGetBean(
String name, @Nullable Class<T> requiredType, @Nullable Object[] args, boolean typeCheckOnly)
throws BeansException {
Object sharedInstance = getSingleton(beanName);
if (mbd.isSingleton()) {
sharedInstance = getSingleton(beanName, () -> {
try {
return createBean(beanName, mbd, args);
}
catch (BeansException ex) {
destroySingleton(beanName);
throw ex;
}
});
beanInstance = getObjectForBeanInstance(sharedInstance, name, beanName, mbd);
}
}这里删掉了一些与本次分析无关的一些代码,首先 doGetBean 方法去获取 Bean 之前,它会去调用 getSingleton 方法获取 Bean 实例,getSingleton 方法实际调用的是 DefaultSingletonBeanRegistry 类的方法,因为 AbstractBeanFactory 间接继承了 DefaultSingletonBeanRegistry,那么我们看一下在 getSingleton 做了哪些操作
@Nullable // 这里使用了双检锁的机制,来保证单例 bean不会被重复创建
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
// 先从一级缓存单例池中获取
Object singletonObject = this.singletonObjects.get(beanName);
// 如果一级缓存没有获取到bean, 并且这个bean正在被创建,说明发生了循环依赖
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
// 进入二级缓存获取bean
singletonObject = this.earlySingletonObjects.get(beanName);
// 如果二级缓存没有获取到bean 并且允许创建早起引用
if (singletonObject == null && allowEarlyReference) {
synchronized (this.singletonObjects) {
// 这里再次尝试从一级缓存获取bean
singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
// 再次尝试从二级缓存获取bean
singletonObject = this.earlySingletonObjects.get(beanName);
// 如果bean还是为空
if (singletonObject == null) {
// 从三级缓存中获取一个lambda表达式,这个表达式会返回一个你需要的bean
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
// 运行lambda表达式获取bean
singletonObject = singletonFactory.getObject();
// 将获取到的bean放入二级缓存
this.earlySingletonObjects.put(beanName, singletonObject);
// 将一级缓存的lambda表达式移除
this.singletonFactories.remove(beanName);
}
}
}
}
}
}
return singletonObject;
}这里假设如果 BeanA 是第一次调用 doGetBean,那么正常来说执行到第一个语句就会返回了,因为此时还并没有把 BenaA 添加到singletonsCurrentlyInCreation集合中标记为正在创建中。所有此时调用 getSingleton 返回的是 NULL。那么我们就会继续往下去执行 doGetBean 的第二个 getSingleton 方法。
// 第二个 getSingleton 方法
public Object getSingleton(String beanName, ObjectFactory<?> singletonFactory) {
synchronized (this.singletonObjects) {
// 这里会再去检查一级缓存单例池是否有这个 Bean 实例
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
// 在这个方法会去检查 Bena 是否正在创建中,并且将 Bean 标记为正在创建中
beforeSingletonCreation(beanName);
// 调用参数 lambda 表达式获取 bean 实例
singletonObject = singletonFactory.getObject();
return singletonObject;
}
}createBean 解析
当我们执行到 singletonObject = singletonFactory.getObject(); 这一行时,其实在执行外部传进来的那个 lambda 表达式,而那个传进来的表达式的 又调用了 createBean(beanName, mbd, args);去创建 Bean,继续往下追踪看 createBean方法做了什么,可以看到 createBean 还没有真正的去创建 Bena 对象,也是调用了 doCreateBean 方法去委托创建 Bean
protected Object createBean(String beanName, RootBeanDefinition mbd, @Nullable Object[] args)
throws BeanCreationException {
// 开始创建 bean 实例
Object beanInstance = doCreateBean(beanName, mbdToUse, args);
return beanInstance;
}doCreateBean 解析
protected Object doCreateBean(String beanName, RootBeanDefinition mbd, @Nullable Object[] args)
throws BeanCreationException {
// 创建 bean 实例
instanceWrapper = createBeanInstance(beanName, mbd, args);
Object bean = instanceWrapper.getWrappedInstance();
// 这里的 PostProcessors 会寻找你的 Bean 的注入点保存起来
applyMergedBeanDefinitionPostProcessors(mbd, beanType, beanName);
// 判断是否允许将 bean 封装成一个 lambda 表达式存入三级缓存
// 可以看到这个条件的判断第一个条件就是必须是单例 Bean 才会允许这样做
// 这也是为什么单例 Bean 无法使用三级缓存解决循环依赖的
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
// 如果 earlySingletonExposure = true 那么就会将 Bean 打包成 lambda 表达式放入三级缓存
if (earlySingletonExposure) {
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
}
Object exposedObject = bean;
// 属性填充和依赖注入
populateBean(beanName, mbd, instanceWrapper);
// 执行 bean 的初始化回调和 aware 回调 AOP 在这里实现
exposedObject = initializeBean(beanName, exposedObject, mbd);
if (earlySingletonExposure) {
// 首先尝试去二级缓存获取 Bean 实例
Object earlySingletonReference = getSingleton(beanName, false);
// 如果二级缓存存在,说明发生了循环依赖,并且在三级缓存放置的那个 lambda 表达式被执行了
if (earlySingletonReference != null) {
// 判断一下经过 initializeBean 的方法执行这个 bean 实例还和初始创建的是否一样
if (exposedObject == bean) {
// 如果一样说明在执行 initializeBean 并未改变 bean 实例,比方说没有在 initializeBean 方法 AOP 过,那么我们直接将二级缓存的 bean 实例作为最终 bean 放入一级缓存即可
exposedObject = earlySingletonReference;
}
else if (!this.allowRawInjectionDespiteWrapping && hasDependentBean(beanName)) {
String[] dependentBeans = getDependentBeans(beanName);
Set<String> actualDependentBeans = new LinkedHashSet<>(dependentBeans.length);
for (String dependentBean : dependentBeans) {
if (!removeSingletonIfCreatedForTypeCheckOnly(dependentBean)) {
actualDependentBeans.add(dependentBean);
}
}
if (!actualDependentBeans.isEmpty()) {
}
}
}
}
return exposedObject;
}总结