从源码角度分析Bean的创建过程
当我们调用 getBean 的时候,Spring 的底层都为我们做了什么呢?又在创建的过程中,为我们提供了那些扩展点,执行顺序又是怎么样的呢?它是如何解决循环依赖的?带着这些疑问,从源码的角度去看一个 Bean 是怎样被创建的。
doGetBean
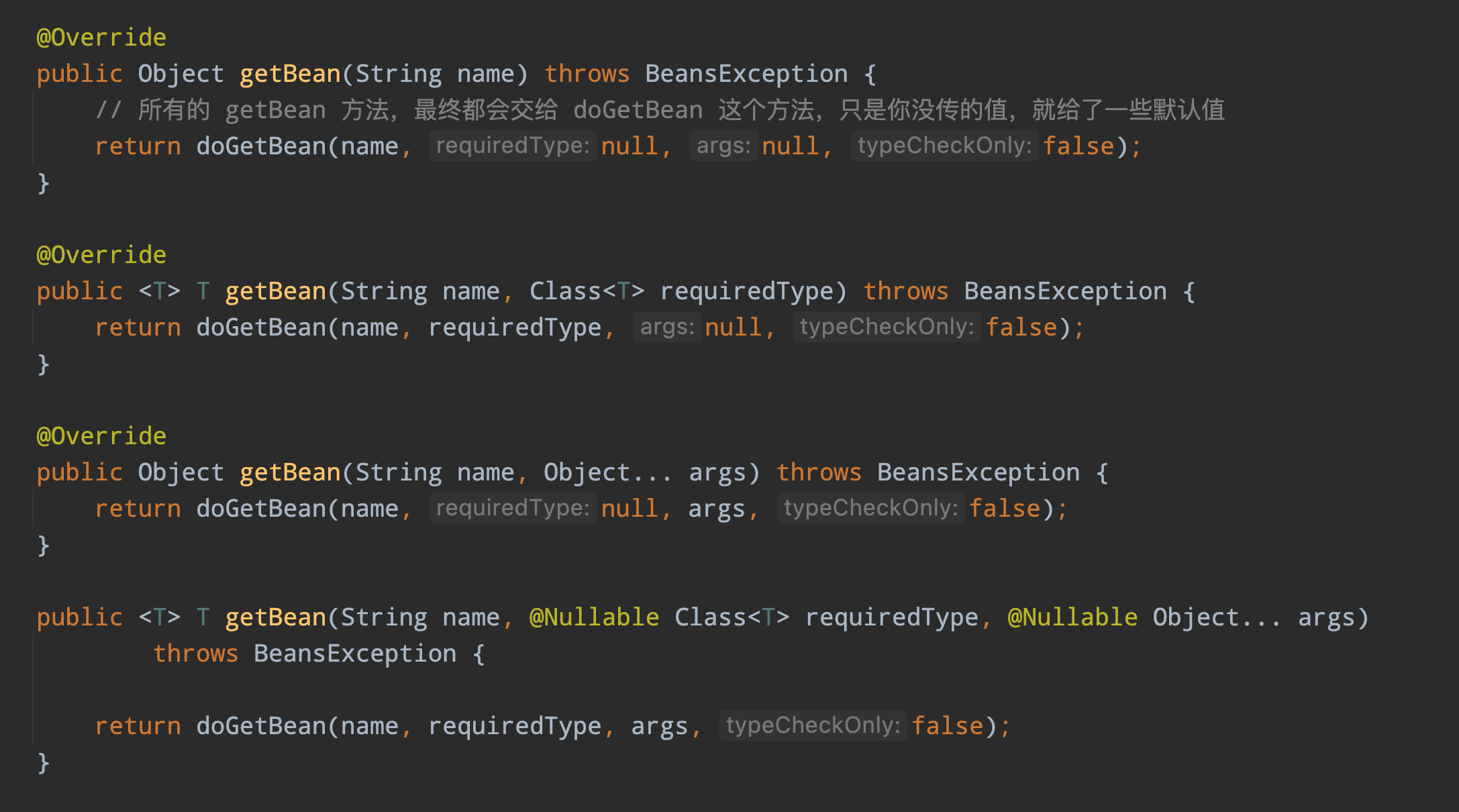
通过上面的图片可以看到,多个 getBean 重载方法都最终交给了 AbstractBeanFactory.class #doGetBean 方法去实现,所以接下来重点分析 doGetBean 这个方法。
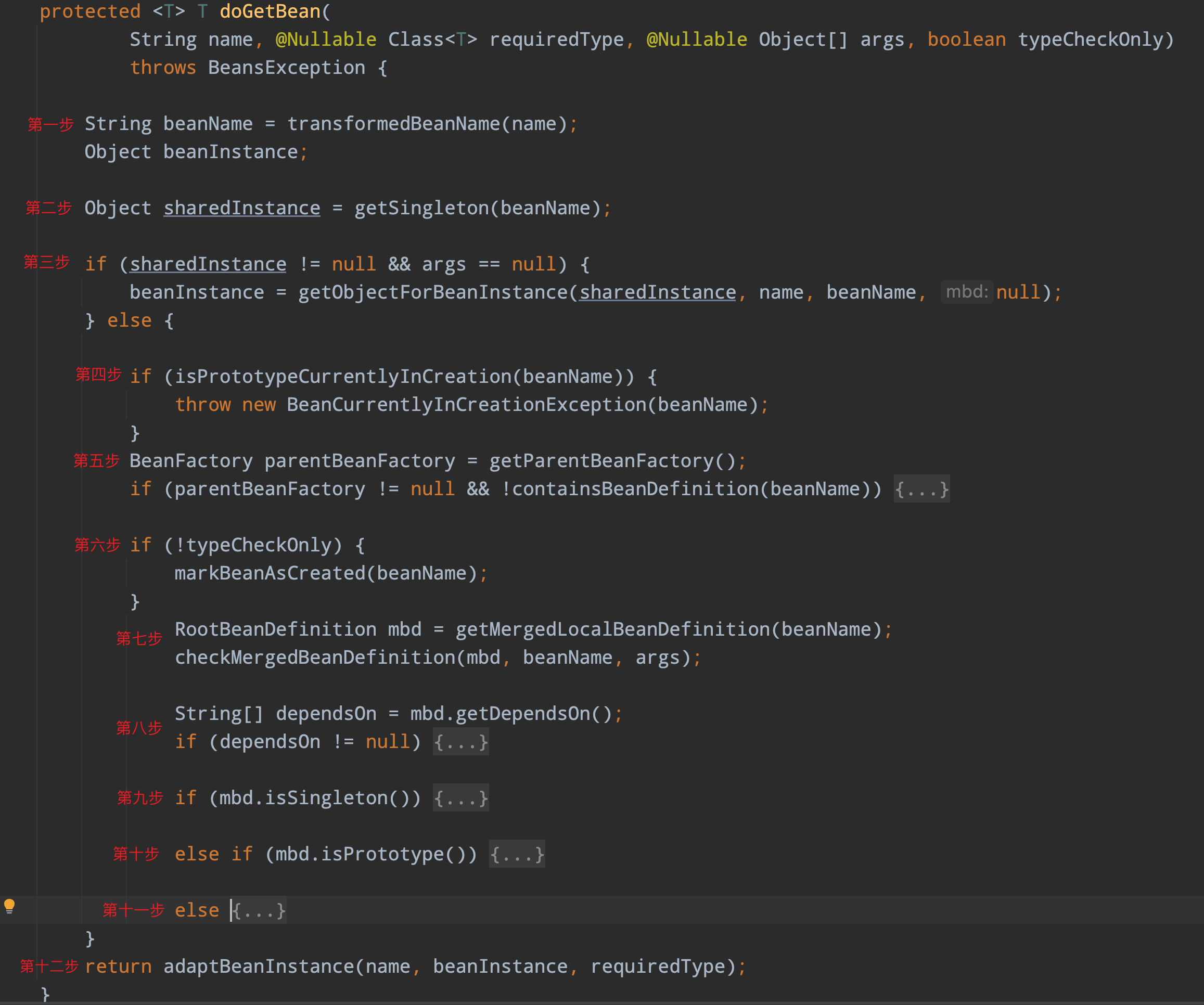
我在 doGetBean 对代码做了一些折叠,然后删除了一些不是很重要与本次分析无关的代码,让我们更加专注于主线,建立一个宏观的流程架构,接下来我先简要的说一下每一步都做了些什么,之后再更加详细的分析每一步的代码都做了些什么。
- 第一步:主要是对参数 name 做了一些转换,因为有可能你传的是一个别名或者你的 name 前缀是 & 符号,Spring 都需要统一转换成 BeanName,以保证下文的一个语义一致性。
- 第二步:先会去单例池中检查是否有创建好的 Bean 对象。
- 第三步:会去结合你传进来的参数 name 和从单例池中获取的 Bean 对象,去推测你到底是需要一个 FactoryBean 还是 FctoryBean#getObject 方法之后的返回值对象。
- 第四步:检查非单例 Bean 是否发生循环依赖。
- 第五步:检查当前自身容器是否有对应的 Bean 实例,没有则委托给父容器(前提是你有父容器)去寻找。
- 第六步:标记这个 Bean 正在创建中。
- 第七步:合并子父 BeanDefinition,检查合并后的 BeanDefinition 是否为抽象。
- 第八步:先处理 @DependsOn 注解的前置依赖。
- 第九步:创建单例 Bean。
- 第十步:创建原型 Bean。
- 第十一步:创建自定义作用域的 Bean,比如 request session。
- 第十二步: 检查创建出来的 Bean 实例,是否与参数传过来的 requireType 能够兼容。
transformedBeanName
第一步:在我们调用 getBean 方法获取 Bean 对象的时候,可能会传别名或者在 name 前面加 & 符号以标识获取 FactoryBean 本身。
先会检查 name 是否以 & 符号开头,有的话去除
public static String transformedBeanName(String name) {
Assert.notNull(name, "'name' must not be null");
// 判断 name 是否以 & 符号开头,如果不是直接返回
if (!name.startsWith(BeanFactory.FACTORY_BEAN_PREFIX)) {
return name;
}
// 循环去除 & 前缀符号,也就是说你有多个都会去除调的
// 比如 &&&beanA => beanA
return transformedBeanNameCache.computeIfAbsent(name, beanName -> {
do {
beanName = beanName.substring(BeanFactory.FACTORY_BEAN_PREFIX.length());
}
while (beanName.startsWith(BeanFactory.FACTORY_BEAN_PREFIX));
return beanName;
});
}然后会去别名注册表找到别名对应的 beanName,在 SimpleAliasRegistry 有一个属性 private final Map<String, String> aliasMap = new ConcurrentHashMap<>(16); 维护了一个别名表,键是别名,值是 beanName。
public String canonicalName(String name) {
String canonicalName = name;
String resolvedName;
do {
resolvedName = this.aliasMap.get(canonicalName);
if (resolvedName != null) {
canonicalName = resolvedName;
}
}
while (resolvedName != null);
return canonicalName;
}上面的代码就是取 aliasMap 别名表寻找别名,但是它这里会去 do while 循环去找,因为有可能第一次找到的 beanName 也是一个别名,不是真正的 beanName,所以相当于递归去找,直到找到为空时才返回。
getSingleton
第二步:当我们把参数 name 转换成为 beanName 后,就会先去缓存中寻找是否有创建好的 Bean,这里它并没有去区分是否为单例或者原型,都会先去缓存中找一遍,代码如下:
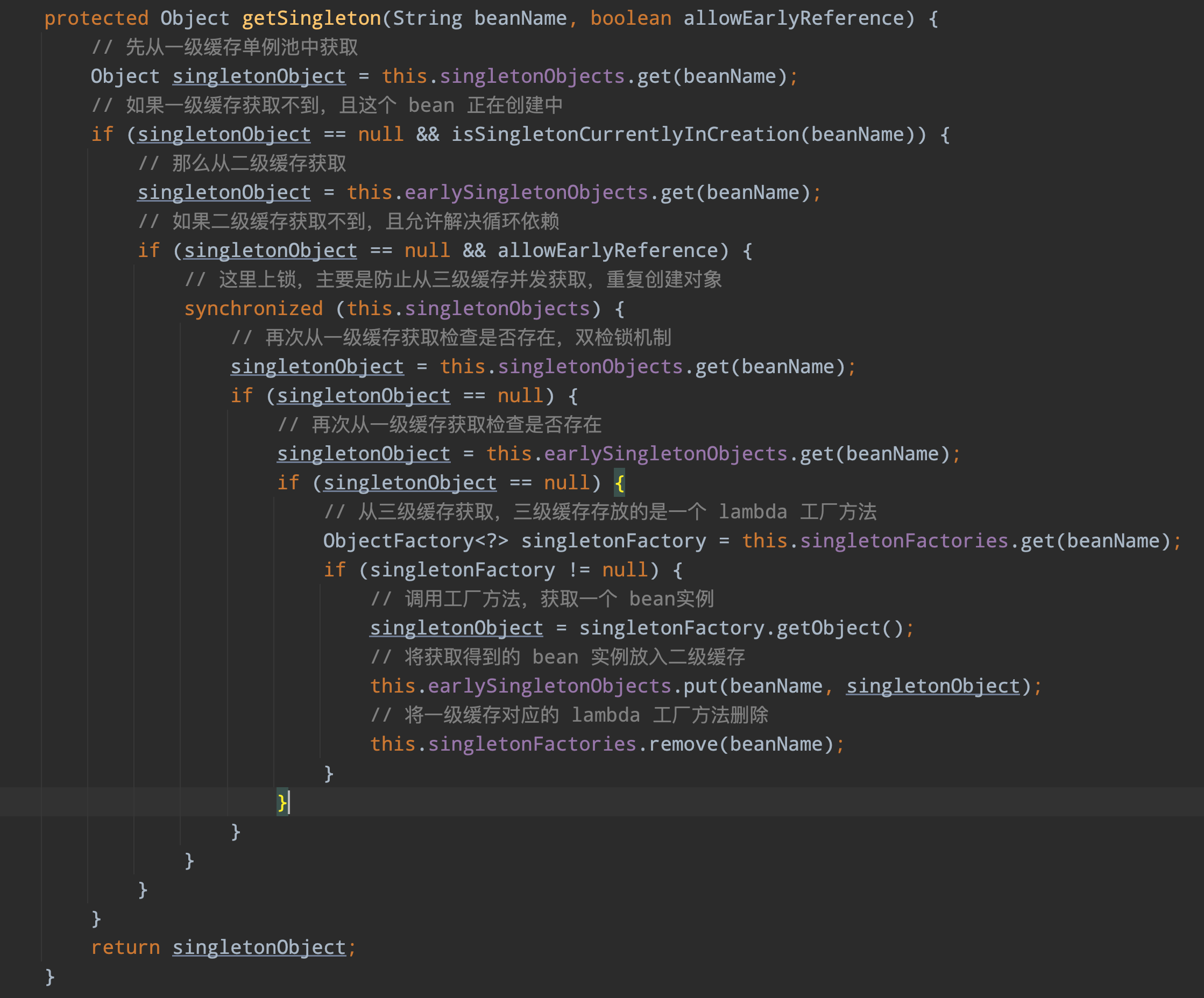
一般来说,如果我们是第一次去获取这个 Bean 的话,当找到第一级缓存就不会往下找了,因为 isSingletonCurrentlyInCreation(beanName) 这个条件现在不会成立,这个条件是判断当前 Bean 是否正在创建中,只有当发生循环依赖这个条件才会成立,因为我们现在还没把这个 Bean 标记为正在创建里中。
getObjectForBeanInstance
第三步:如果在第二步的时候,我们从单例池中获取到了 Bean 对象,按理来说就可以返回了啊,为什么还要去调用了 getObjectForBeanInstance 方法了,因为这是为了支持 FactoryBean。先看一个例子,然后再来分析源码:
public class BeanB {
}
public class BeanA implements FactoryBean<BeanB> {
@Override
public BeanB getObject() throws Exception {
return new BeanB();
}
@Override
public Class<?> getObjectType() {
return BeanB.class;
}
}
public class FactoryBeanDemo {
public static void main(String[] args) {
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext();
context.register(BeanA.class);
context.refresh();
System.out.println(context.getBean("beanA"));
}
}先思考一下,在上面的这段代码中,System.out.println(context.getBean("beanA")); 打印的是 BeanA 还是 BeanB,你可能以为是 BeanA,但实际是 BeanB,你可以试着跑一下这段代码,源代码见:com.demo1。那么如果我就是需要获取 BeanA 这个对象了,那么你只需要在 beanName 前面加一个前缀 & 符号,就代码获取的 BeanFactory 本身。而造成这样效果的就是 getObjectForBeanInstance 在发挥作用。
protected Object getObjectForBeanInstance(
Object beanInstance, String name, String beanName, @Nullable RootBeanDefinition mbd) {
// 判断 name 是否以 & 符号开头
if (BeanFactoryUtils.isFactoryDereference(name)) {
if (beanInstance instanceof NullBean) {
return beanInstance;
}
// 如果 name 是以 & 符号开头,但是又不是 FactoryBean 类型,那么抛异常
if (!(beanInstance instanceof FactoryBean)) {
throw new BeanIsNotAFactoryException(beanName, beanInstance.getClass());
}
if (mbd != null) {
mbd.isFactoryBean = true;
}
// 这里判断出 name 是以 & 符号开头,说明你想获取的就是 FactoryBean 这个对象本身,直接返回即可
return beanInstance;
}
// 这里 beanInstance 是不是一个 FactoryBean
// 如果不是直接返回了,因为接下来的操作就是调用 FactoryBean 的 getObject 方法
if (!(beanInstance instanceof FactoryBean)) {
return beanInstance;
}
Object object = null;
if (mbd != null) {
mbd.isFactoryBean = true;
}
else {
// 先检查一下缓存中是否有对应的 bean 实例
object = getCachedObjectForFactoryBean(beanName);
}
if (object == null) {
// 将 beanInstance 强制转换成 FactoryBean 类型
FactoryBean<?> factory = (FactoryBean<?>) beanInstance;
if (mbd == null && containsBeanDefinition(beanName)) {
// 合并 beanDefinition,合并子父 beanBeanDefinition
mbd = getMergedLocalBeanDefinition(beanName);
}
boolean synthetic = (mbd != null && mbd.isSynthetic());
// 调用 FactoryBean getObject 方法获取对象
object = getObjectFromFactoryBean(factory, beanName, !synthetic);
}
return object;
}isPrototypeCurrentlyInCreation
第四步:这一步主要检查非单例 Bean 是否发生了循环依赖,主要工作原理就是在创建非单例 Bean 的时候,会将 BeanName 放置到 ThreadLocal 当中。代码如下:
protected boolean isPrototypeCurrentlyInCreation(String beanName) {
Object curVal = this.prototypesCurrentlyInCreation.get();
return (curVal != null &&
(curVal.equals(beanName) || (curVal instanceof Set && ((Set<?>) curVal).contains(beanName))));
}下面是创建原型 Bean 的时候前置操作:
protected void beforePrototypeCreation(String beanName) {
Object curVal = this.prototypesCurrentlyInCreation.get();
if (curVal == null) {
this.prototypesCurrentlyInCreation.set(beanName);
}
else if (curVal instanceof String) {
Set<String> beanNameSet = new HashSet<>(2);
beanNameSet.add((String) curVal);
beanNameSet.add(beanName);
this.prototypesCurrentlyInCreation.set(beanNameSet);
}
else {
Set<String> beanNameSet = (Set<String>) curVal;
beanNameSet.add(beanName);
}
}如果依赖的两方都是原型 Bean 的话,即使是属性循环依赖也无法解决会抛出异常,但是如果有一方是单例 Bean 的话,那么 Spring 可以解决这种循环依赖。
getParentBeanFactory
第五步:如果当前容器不存在该 Bean 对应的 BeanDefinition,会委托父容器去寻找找创建(如果有父容器的话),代码如下:
BeanFactory parentBeanFactory = getParentBeanFactory();
if (parentBeanFactory != null && !containsBeanDefinition(beanName)) {
// Not found -> check parent.
String nameToLookup = originalBeanName(name);
if (parentBeanFactory instanceof AbstractBeanFactory) {
return ((AbstractBeanFactory) parentBeanFactory).doGetBean(
nameToLookup, requiredType, args, typeCheckOnly);
}
else if (args != null) {
// Delegation to parent with explicit args.
return (T) parentBeanFactory.getBean(nameToLookup, args);
}
else if (requiredType != null) {
// No args -> delegate to standard getBean method.
return parentBeanFactory.getBean(nameToLookup, requiredType);
}
else {
return (T) parentBeanFactory.getBean(nameToLookup);
}
}markBeanAsCreated
第六步:将当前的 Bean 标记为正在创建中,代码如下:
protected void markBeanAsCreated(String beanName) {
if (!this.alreadyCreated.contains(beanName)) {
synchronized (this.mergedBeanDefinitions) {
if (!this.alreadyCreated.contains(beanName)) {
// 设置 beanDefinition 需要重新合并
clearMergedBeanDefinition(beanName);
// 将当前 beanName 添加到 alreadyCreated Set集合
// 表示当前 bean 正在创建中,为检查是否发生循环依赖做准备
this.alreadyCreated.add(beanName);
}
}
}
}getMergedLocalBeanDefinition
第七步:判断当前 BeanDefinition 是否有父 BeanDefinition,然后父 BeanDefinition 还有父的话,会先合并的父的父,一直递归往上合并,合并的原则就是,子类没有定义的继承父类,子类定义的使用子类自己的。合并完 BeanDefinition 后,还会去检查这个 BeanDefinition 是否为抽象的,如果是抽象的抛异常。源代码见:com.demo2
public class MergedLocalBeanDefinitionDemo {
public static void main(String[] args) {
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext();
// 父 BeanDefinition
BeanDefinitionBuilder parentBd = BeanDefinitionBuilder.genericBeanDefinition();
AbstractBeanDefinition parentBeanDefinition = parentBd.getBeanDefinition();
parentBeanDefinition.setAbstract(true);
parentBeanDefinition.setScope(ConfigurableBeanFactory.SCOPE_PROTOTYPE);
// 子 BeanDefinition
BeanDefinitionBuilder childBd = BeanDefinitionBuilder.genericBeanDefinition();
AbstractBeanDefinition childBeanDefinition = childBd.getBeanDefinition();
childBeanDefinition.setBeanClass(BeanA.class);
childBeanDefinition.setParentName("parentBd");
context.registerBeanDefinition("parentBd",parentBeanDefinition);
context.registerBeanDefinition("childBd",childBeanDefinition);
context.refresh();
System.out.println(context.getBean("childBd"));
System.out.println(context.getBean("childBd"));
System.out.println(context.getBean("childBd"));
}
}上面的代码中,我定义了父 BeanDefinition parentBd,子 BeanDefinition childBd,通过子 BeanDefinition#setParentName 方法指定父 BeanDefinition beanName。parentBd 指定 scope 属性为 prototype,由于子 BeanDefinition 并未指定 scope 属性,所以继承了父类,最终子 BeanDefinition 所产生的 Bean 对象也变成了原型的。
DependsOn
第八步:处理 @DependsOn 注解,当你希望在创建 BeanA 的时候,希望先创建 BeanB,那么你可以这样做:
@DependsOn({"beanB"})
public class BeanA {
}但是如果你写出这样的代码的话,那么会发生循环依赖,从而抛出异常:
@DependsOn({"beanB"})
public class BeanA {
}
@DependsOn({"beanA"})
public class BeanB {
}具体实现代码如下,在 BeanDefinition 有一个 private String[] dependsOn 属性,保存你所需要的前置依赖 Bean,然后在这一步获取出来遍历创建
// 在创建 Bean 之前,先处理 @DependsOn 注解的依赖
String[] dependsOn = mbd.getDependsOn();
if (dependsOn != null) {
for (String dep : dependsOn) {
// 判断是否发生循环依赖
if (isDependent(beanName, dep)) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName,
"Circular depends-on relationship between '" + beanName + "' and '" + dep + "'");
}
// 注册依赖关系
registerDependentBean(dep, beanName);
try {
// 先创建依赖的 bean
getBean(dep);
}
catch (NoSuchBeanDefinitionException ex) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName,
"'" + beanName + "' depends on missing bean '" + dep + "'", ex);
}
}
}创建单例Bean
第九步:这一步会去判断你的 BeanDefinition 是不是一个单例 Bean,如果是的话在这里创建:
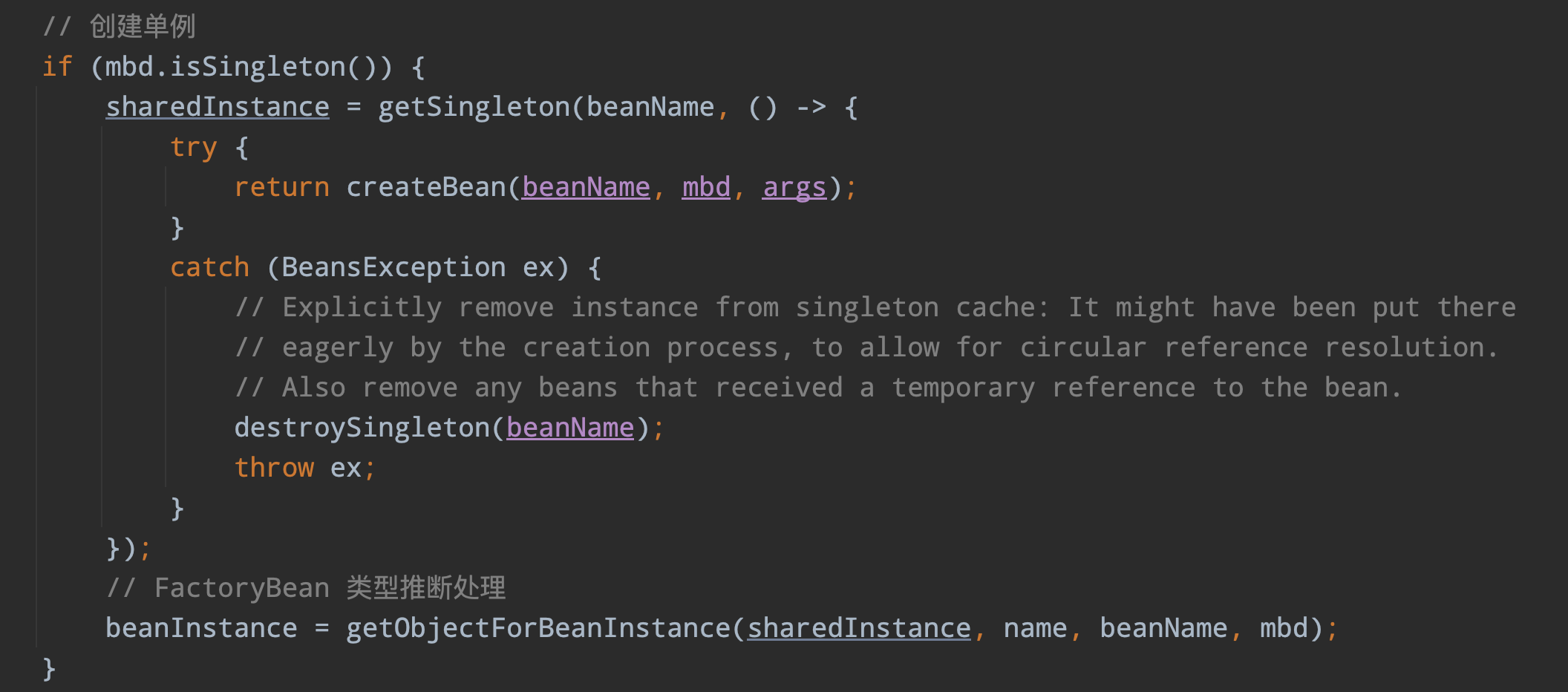
这里调用了 getSingleton 方法,然后还传了一个 lambda 表达式,在 getSingleton 方法里,会再次去单例池中检查一遍 Bean 是否存在了,如果此时还不存在的话,就会调用参数传进去的 lambda 表达式创建一个 Bean,所以创建 Bean 的主要逻辑还是在 lambda 表达式的 return createBean(beanName, mbd, args); 这行代码,这里先不分析 createBean 这个方法,因为不管是创建单例 Bean,还是原型 Bean,亦或是自定义作用域的 Bean 最终都是走的这个方法,所以放到最后再来分析。我们先看下 getSingleton 这个方法做了那些事情:
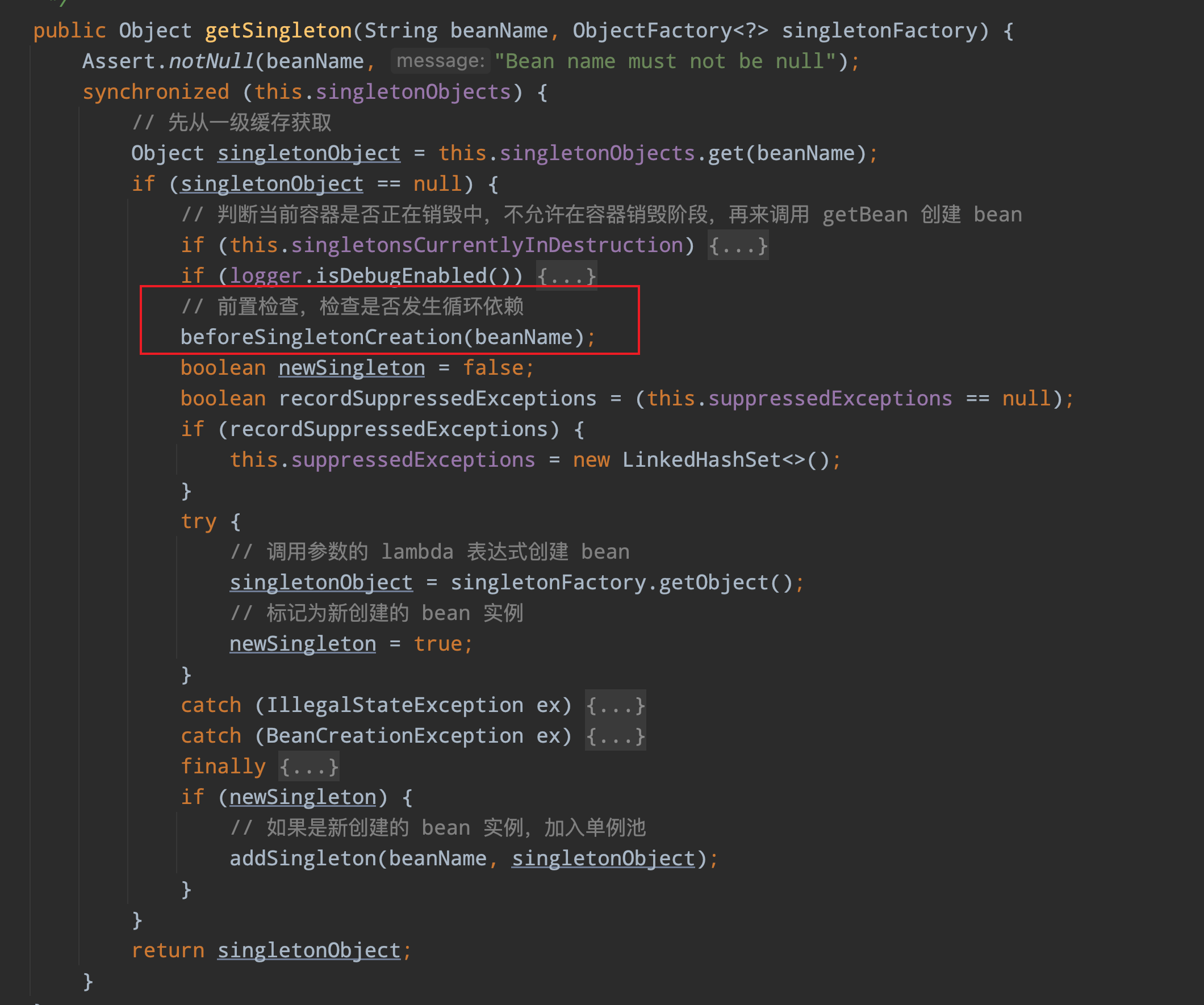
重点看一下 beforeSingletonCreation 这个方法
protected void beforeSingletonCreation(String beanName) {
if (!this.inCreationCheckExclusions.contains(beanName) && !this.singletonsCurrentlyInCreation.add(beanName)) {
throw new BeanCurrentlyInCreationException(beanName);
}
}这里尝试将 beanName 添加到 singletonsCurrentlyInCreation 集合
private final Set<String> singletonsCurrentlyInCreation =
Collections.newSetFromMap(new ConcurrentHashMap<>(16));因为 singletonsCurrentlyInCreation 是 Set 集合,如果重复添加添加的话会返回 FALSE,Spring 就是依靠这个集合来判断是否发生循环依赖。
创建原型Bean
第十步:创建原型多例Bean,就相对简单对了,直接调用createBean 每次都创建一个新的 Bean 对象返回,beforePrototypeCreation 方法第四步已经分析过了,这里就不展开了,主要就是把当前创建的 beanName 放到 ThreadLcoal,标记这个正在创建中,用于检查循环依赖。
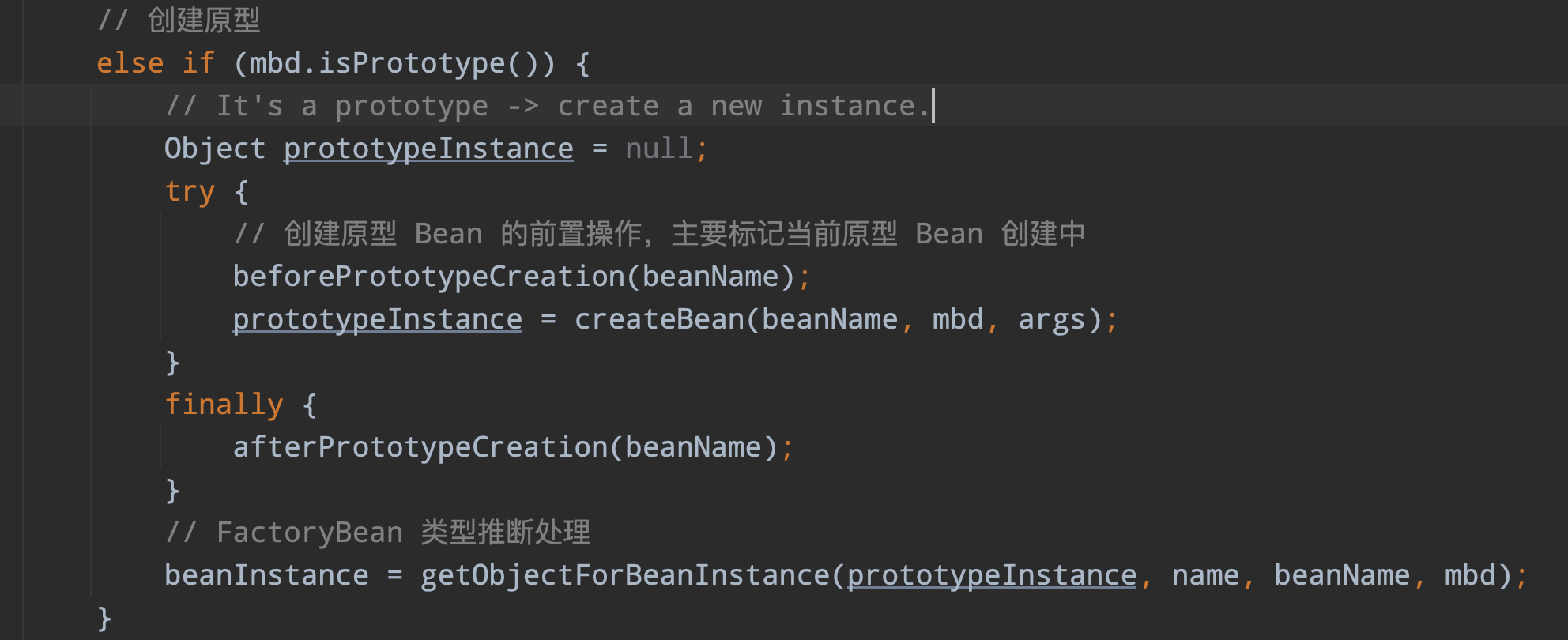
而 finally 代码块的 afterPrototypeCreation 方法自然就是释放 ThreadLocal 的内存了
protected void afterPrototypeCreation(String beanName) {
Object curVal = this.prototypesCurrentlyInCreation.get();
if (curVal instanceof String) {
this.prototypesCurrentlyInCreation.remove();
}
else if (curVal instanceof Set) {
Set<String> beanNameSet = (Set<String>) curVal;
beanNameSet.remove(beanName);
if (beanNameSet.isEmpty()) {
this.prototypesCurrentlyInCreation.remove();
}
}
}创建自定义作用域的Bean
第十一步:首先会通过 BeanDefinition 获取 scope 类型名字,然后拿着 scopeName 去获取一个 Scope 对象,而 Scope#get 方法有点类似于创建单例 Bean 的 getSingleton 方法,就是先去你自己的作用域去找,如果没找到的话,再去调用参数 lambda 表达式创建一个。
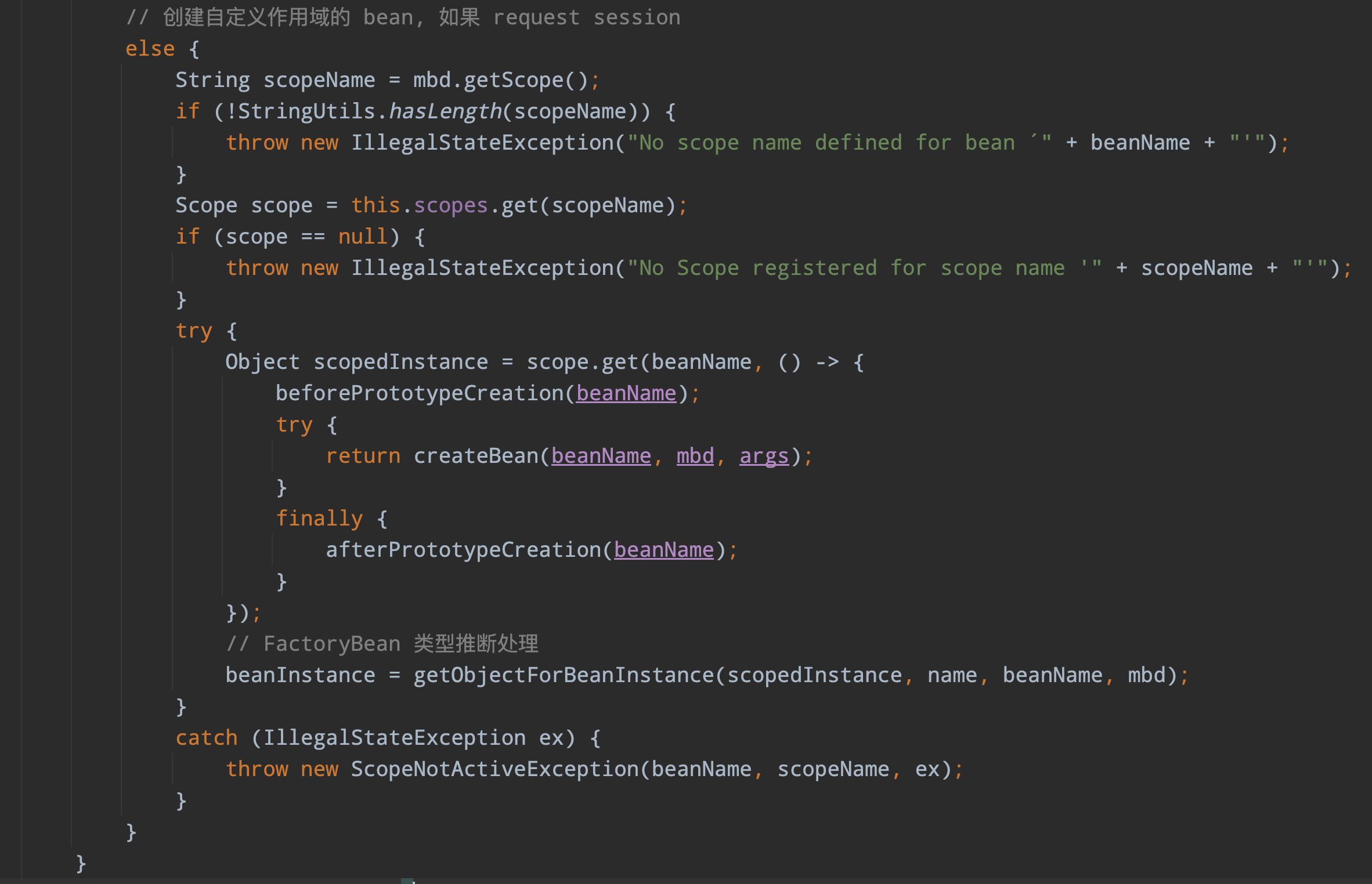
另外 beforePrototypeCreation 和 afterPrototypeCreation 也是用的和创建单例 Bean 的同一套逻辑,这里就不赘述了。
接下来实现一个自定义 Scope 作用域,方便更加加深理解,底层的原则原理,源代码见:com.demo3
@Scope(scopeName = "myScope",proxyMode = ScopedProxyMode.TARGET_CLASS)
public class BeanB {
}
public class BeanA {
@Autowired
private BeanB beanB;
public void test() {
String name = Thread.currentThread().getName();
System.out.println(name + ": " + beanB);
}
}
// 一个简单的 ThreadLocal 工具类
public class ThreadContext {
private final static ThreadLocal<Map<String, Object>> context = new ThreadLocal<>();
public static Object get(String key) {
Map<String, Object> map = context.get();
if (Objects.isNull(map)) {
map = new HashMap<>();
context.set(map);
return null;
}
return context.get().get(key);
}
public static void set(String key, Object value) {
Map<String, Object> map = context.get();
if (Objects.isNull(map)) {
map = new HashMap<>();
}
map.put(key, value);
}
public static void remove() {
context.remove();
}
}
// 实现 Scope 接口,来自定义作用域
public class MyScope implements Scope {
@Override
public Object get(String name, ObjectFactory<?> objectFactory) {
Object obj = ThreadContext.get(name);
if (Objects.isNull(obj)) {
obj = objectFactory.getObject();
ThreadContext.set(name, obj);
}
return obj;
}
@Override
public Object remove(String name) {
Object obj = ThreadContext.get(name);
ThreadContext.remove();
return obj;
}
@Override
public void registerDestructionCallback(String name, Runnable callback) {
}
@Override
public Object resolveContextualObject(String key) {
return null;
}
@Override
public String getConversationId() {
return null;
}
}
// 将我们的 MyScope 自定义作用域类放到容器
public class RegisterScopeBeanFactoryPostProcessor implements BeanFactoryPostProcessor {
@Override
public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException {
beanFactory.registerScope("myScope",new MyScope());
}
}
// 启动两个线程来模拟两个请求,到此基本了实现了类似的 request 作用域
public class ScopeDemo {
public static void main(String[] args) {
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext();
context.register(RegisterScopeBeanFactoryPostProcessor.class);
context.register(BeanA.class);
context.register(BeanB.class);
context.refresh();
ThreadPoolExecutor threadPoolExecutor =
new ThreadPoolExecutor(3, 5, 100L,
TimeUnit.SECONDS, new ArrayBlockingQueue<>(5));
Runnable runnable = () -> {
BeanA bean = context.getBean(BeanA.class);
for (int i = 0; i < 10; i++) {
bean.test();
try {
Thread.sleep(1000L);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
};
threadPoolExecutor.execute(runnable);
threadPoolExecutor.execute(runnable);
}
}adaptBeanInstance
第十二步:这一步主要检查创建出来的 bean 实例,是否与参数传过来的 requireType 能够兼容,代码如下:
<T> T adaptBeanInstance(String name, Object bean, @Nullable Class<?> requiredType) {
// requiredType.isInstance(bean) 类型相同返回 true
// requiredType.isInstance(bean) 如果是bean的父类返回 true
// requiredType.isInstance(bean) bean的子类返回 false
if (requiredType != null && !requiredType.isInstance(bean)) {
try {
// 尝试进行类型转换
Object convertedBean = getTypeConverter().convertIfNecessary(bean, requiredType);
if (convertedBean == null) {
throw new BeanNotOfRequiredTypeException(name, requiredType, bean.getClass());
}
return (T) convertedBean;
}
catch (TypeMismatchException ex) {
if (logger.isTraceEnabled()) {
logger.trace("Failed to convert bean '" + name + "' to required type '" +
ClassUtils.getQualifiedName(requiredType) + "'", ex);
}
throw new BeanNotOfRequiredTypeException(name, requiredType, bean.getClass());
}
}
return (T) bean;
}到这里 doGetBean 方法总体流程分析完了,但是还有一个最重要的 createBean 方法还未分析,其实分析到这里都还没有设计真正创建 Bean 的代码,因为无论是创建单例、原型、自定义作用域,如果缓存没获取到的话,都会调用 createBean 方法来创建,所以放到最后再来统一分析。
createBean
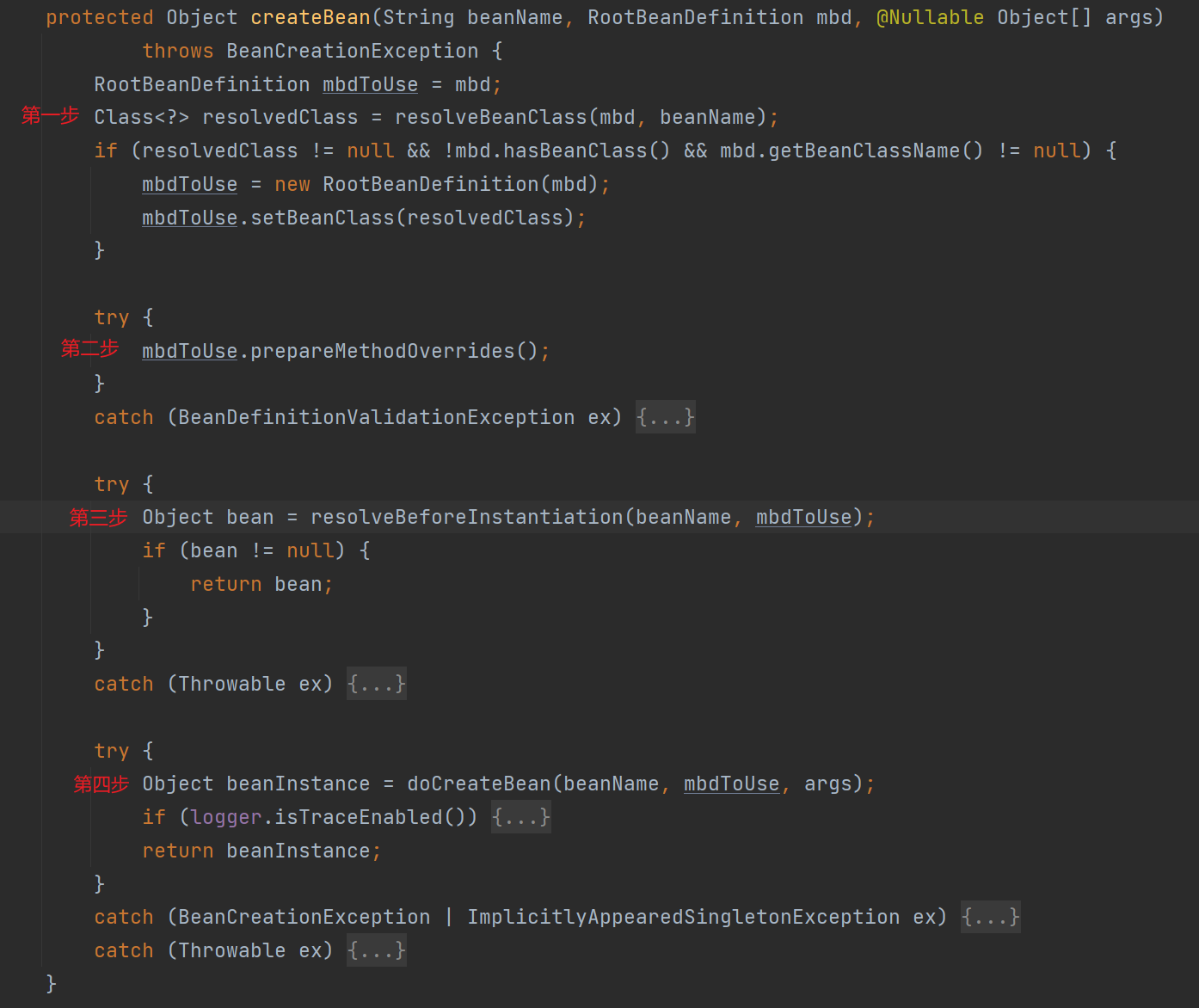
- 第一步:加载 BeanDefinition 对应的 Class 对象。
- 第二步:检查是否有方法替换,如果有的话检查替换的方法是否有重载。
- 第三步:实例化前的 Bean 后置处理器回调。
- 第四步:在这一步才会去正在创建 Bean 实例。
resolveBeanClass
第一步:会先检查 BeanDefinition 的 beanClass 属性是否为一个 Class 对象,因为我们在扫描类加载包装成 BeanDefinition 的时候,其实并没有加载对应的 Class 对象,只是将 Class 对应的全类名记录到了 beanClass 属性上。可以看到 BeanDefinition 的 beanClass 属性是一个 Object 类型,而非 Class 类型。
private volatile Object beanClass;那么它是用扫描类加载器去加载这个类的了?默认使用的是 ClassUtils#getDefaultClassLoader() 方法去获取类加载器的:
public static ClassLoader getDefaultClassLoader() {
ClassLoader cl = null;
try {
// 首先检查当前线程上下文是否有设置 ClassLoader
cl = Thread.currentThread().getContextClassLoader();
}
catch (Throwable ex) {
// Cannot access thread context ClassLoader - falling back...
}
if (cl == null) {
// 线程上下文没有找到,使用加载 ClassUtils 的类加载器
cl = ClassUtils.class.getClassLoader();
if (cl == null) {
// getClassLoader() returning null indicates the bootstrap ClassLoader
try {
// 最后没有找到的话,使用系统类加载器
cl = ClassLoader.getSystemClassLoader();
}
catch (Throwable ex) {
// Cannot access system ClassLoader - oh well, maybe the caller can live with null...
}
}
}
return cl;
}加载 Class 对象成功后,会将当前加载的 Class 对象属性赋值到 BeanDefinition 的 beanClass 属性上,下次创建 Bean 实例时,直接复用即可,不需要重复加载了。另外完成类加载后,还会将当前的 BeanDefinition 重新赋值深拷贝一份,主要是因为后面的 Bean 后置处理器,会有可能修改 BeanDefinition,所以这里就 Copy 了一份,保证缓存中的不被影响。
prepareMethodOverrides
第二步:这一步主要是检查是否有方法替换,如果有的话检查替换的方法是否有重载。那什么是方法替换了?先看一个例子,比方说我下面代码这个类有一个无参的和一个有参的 test 方法,我希望运行时把他替成另一种实现,那么就可以使用方法替换:
public class BeanA {
public void test(){
System.out.println("BeanA test");
}
public void test(String str){
System.out.println("BeanA test "+str);
}
}具体实现代码如下,源代码见:com.demo4
Spring.xml
<bean id="beanA" class="com.demo4.BeanA">
<replaced-method name="test" replacer="beanB"/>
<replaced-method name="test" replacer="beanC">
<arg-type match="java.lang.String"></arg-type>
</replaced-method>
</bean>
<bean id="beanB" class="com.demo4.BeanB"/>
<bean id="beanC" class="com.demo4.BeanC"/>// 导入配置文件
@ImportResource({"PrepareMethodOverrides.xml"})
public class AppConfig {
@Bean
public BeanA beanA(){
return new BeanA();
}
}
// 替换 BeanA 无参的 test 方法
public class BeanB implements MethodReplacer {
@Override
public Object reimplement(Object obj, Method method, Object[] args) throws Throwable {
System.out.println("替换 BeanA test 有参");
return null;
}
}
// 替换 BeanA 参数类型为 String 的 test ff
public class BeanC implements MethodReplacer {
@Override
public Object reimplement(Object obj, Method method, Object[] args) throws Throwable {
System.out.println("替换 BeanA test 有参"+ Arrays.toString(args));
return null;
}
}具体检查代码如下
protected void prepareMethodOverride(MethodOverride mo) throws BeanDefinitionValidationException {
// 根据替换的方法名字去获取类中所有的方法
int count = ClassUtils.getMethodCountForName(getBeanClass(), mo.getMethodName());
if (count == 0) {
throw new BeanDefinitionValidationException(
"Invalid method override: no method with name '" + mo.getMethodName() +
"' on class [" + getBeanClassName() + "]");
}
else if (count == 1) {
// 如果这个方法名字,只获取到一个,说明没有重载方法,将这里标记为false
// 那么后面去实际调用的时候,就可以避免参数类型检查的开销
mo.setOverloaded(false);
}
}resolveBeforeInstantiation
第三步:回调 InstantiationAwareBeanPostProcessor 接口的 postProcessBeforeInstantiation 方法,对 Bean 进行实例化之前处理,会将当前的 Bean 的 Class 对象和 beanName:
public interface InstantiationAwareBeanPostProcessor extends BeanPostProcessor {
default Object postProcessBeforeInstantiation(Class<?> beanClass, String beanName) throws BeansException {
return null;
}
}如果你在一步返回了一个对象,非 null 的话,那么会进一步进行回调 BeanPostProcessor 接口的 postProcessAfterInitialization 方法,初始化后处理,会将当前产生的 Bean 对象和 beanName 传递给这个方法:
public interface BeanPostProcessor {
default Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
return bean;
}
}如果你再 postProcessAfterInitialization 回调的话,会中断接口回调循环有可能导致后面的回调无法执行(因为可能存在多个 Bean 后置处理器),并将参数对象直接返回,但是如果你返回了一个新的对象,那么会将你返回的对象作为最终返回对象,当然不排除会被后面执行的 Bean 后置处理器给覆盖。
如果在 resolveBeforeInstantiation 这个步骤中返回了对象的话,那么 Spring 就会直接将使用这个方法返回的对象作为 Bean 实例返回。
Object bean = resolveBeforeInstantiation(beanName, mbdToUse);
if (bean != null) {
// 如果 resolveBeforeInstantiation 方法返回结果不为 null,直接将获取到的 bean 返回
return bean;
}doCreateBean
由于 doCreateBean 方法流程比较多,就单独列出来再分析。
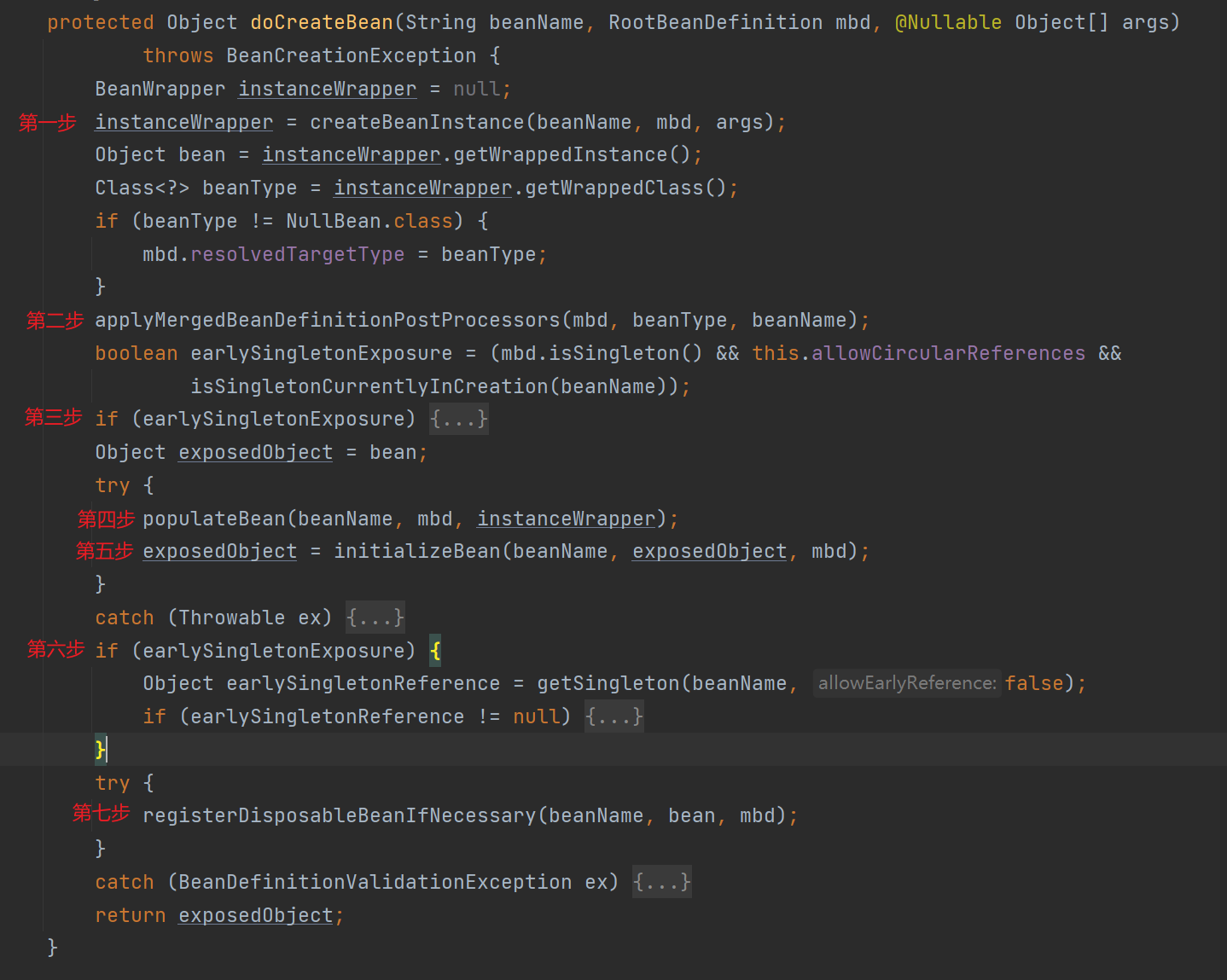
- 第一步:创建 Bean 实例,并使用 BeanWrapper 装饰器模式包装返回。
- 第二步:回调 MergedBeanDefinitionPostProcessor # postProcessMergedBeanDefinition 方法。
- 第三步:判断是否允许处理循环依赖,如果允许的话,将 Bean 实例放入三级缓存。
- 第四步:属性依赖注入。
- 第五步:执行初始化回调。
- 第六步:检查对象一致性。
- 第七步:注册 Bean 销毁时回调方法。
createBeanInstance
第一步:会去创建 Bean 实例,并通过 BeanWrapper 包装返回。首先会再次去调用 resolveBeanClass 检查 Class 是否已经解析加载完成,并且是 public 可访问的。然后在创建 Bean 实例之前,还会去检查 BeanDefnition 是否有设置 Supplier<?> 属性,Supplier<?> 是 JDK 提供的一个函数式接口,用来返回一个对象,如果有设置的话,直接调用这个函数式接口获取一个对象,并用这个对象作为 Bean 实例返回,不会再去创建 Bean 实例了,运行下面的代码,源代码见com.demo5:
public class SupplierDemo {
public static void main(String[] args) {
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext();
AbstractBeanDefinition supplierBd = BeanDefinitionBuilder.genericBeanDefinition().getBeanDefinition();
supplierBd.setBeanClass(BeanA.class);
supplierBd.setInstanceSupplier((Supplier<BeanA>) () -> {
BeanA beanA = new BeanA();
System.out.println("Supplier: " + beanA);
return beanA;
});
context.registerBeanDefinition("beanA", supplierBd);
context.refresh();
System.out.println("Context: "+context.getBean(BeanA.class));
}
}你会发现,两处打印的 beanA 对象都是同一个对象,说明 Spring 并未自己创建对象,而是调用了 Supplier 接口的 get 方法获取的对象返回。
如果未设置 Supplier<?> 属性的话,再去检查是否有设置 factoryMethodName 属性,如果有的话会去当前 BeanDefinition 所属类的类中找名字是 factoryMethodName 的方法,该方法必须 static 修饰的,然后调用该方法获取一个对象,作为 Bean 实例返回,Spring 也不会再去创建了。
public class BeanA {
public static BeanA ssBeanA(){
BeanA beanA = new BeanA();
System.out.println("FactoryMethod: "+beanA);
return beanA;
}
}
public class FactoryMethodNameDemo {
public static void main(String[] args) {
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext();
AbstractBeanDefinition factoryMethodNameBd = BeanDefinitionBuilder.genericBeanDefinition().getBeanDefinition();
factoryMethodNameBd.setBeanClass(BeanA.class);
factoryMethodNameBd.setFactoryMethodName("ssBeanA");
context.refresh();
context.registerBeanDefinition("beanA",factoryMethodNameBd);
System.out.println("Context: "+context.getBean("beanA"));
}
}如果 Supplier 和 factoryMethodName 都没有设置值的话,接下里会检查是否有缓存的构造函数可用,只有当你 getBean 没有参数没有传 Object... args 时,这个缓存才会生效,一般来说,只有对非单例 Bean 才可能会有用。
boolean resolved = false;
boolean autowireNecessary = false;
if (args == null) {
synchronized (mbd.constructorArgumentLock) {
// 检查是否有缓存的构造方法
if (mbd.resolvedConstructorOrFactoryMethod != null) {
// resolved = true 表示有缓存的构造方法可用
resolved = true;
// 判断是否需要通过有参构造函数创建
autowireNecessary = mbd.constructorArgumentsResolved;
}
}
}
if (resolved) {
if (autowireNecessary) {
// 有缓存的有参构造方法创建
return autowireConstructor(beanName, mbd, null, null);
}
else {
// 有缓存的无参构造方法创建
return instantiateBean(beanName, mbd);
}
}接下来就会进行构造方法推断,决定到底使用哪一个构造方法来创建 Bean 实例,首先回调 SmartInstantiationAwareBeanPostProcessor 接口的 determineCandidateConstructors 方法获取一些可用的构造方法,其中 Spring 内置实现的 AutowiredAnnotationBeanPostProcessor 会在这里解析是否有 @Autowired 标注的构造方法。
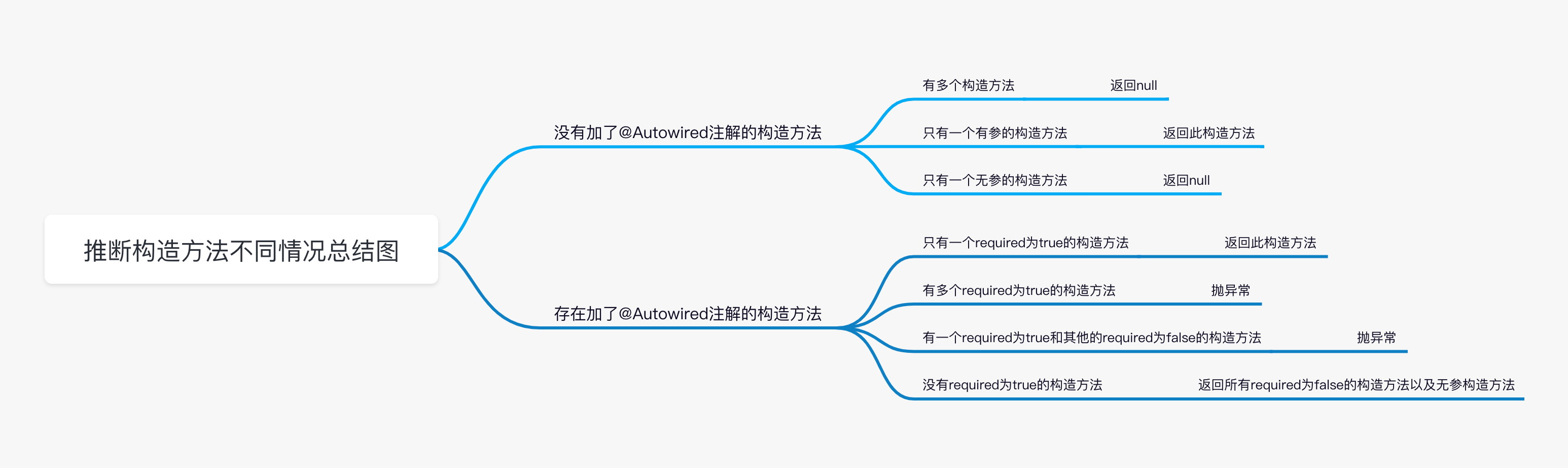
另外 AutowiredAnnotationBeanPostProcessor 除了会解析 @Autowired 注解以为,还会在 determineCandidateConstructors 解析 @Value 和 @Lookup 注解。
postProcessMergedBeanDefinition
第二步:经过第一步以后,已经成功的创建了 Bean 实例,但此时的 Bean 实例还未进行属性注入,Bean对象实例化出来之后,接下来就应该给对象的属性赋值了。在真正给属性赋值之前,Spring又 提供了一个扩展点,在这里会回调 MergedBeanDefinitionPostProcessor 接口的 postProcessMergedBeanDefinition 方法,此时我们可以基于此接口进行扩展,修改 BeanDefinition 完成一些自定义的属性注入,源代码见:com.demo6
public class BeanA {
private String name;
public void setName(String name) {
this.name = name;
}
public String getName(){
return this.name;
}
}
public class MyMergedBeanDefinitionPostProcessor implements MergedBeanDefinitionPostProcessor {
@Override
public void postProcessMergedBeanDefinition(RootBeanDefinition beanDefinition, Class<?> beanType, String beanName) {
if ("beanA".equals(beanName)){
beanDefinition.getPropertyValues().add("name","李四");
}
}
}
public class MergedBeanDefinitionPostProcessorDemo {
public static void main(String[] args) {
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext();
context.register(BeanA.class);
context.register(MyMergedBeanDefinitionPostProcessor.class);
context.refresh();
BeanA bean = context.getBean(BeanA.class);
System.out.println(bean.getName());
}
}在 Spring 源码中,AutowiredAnnotationBeanPostProcessor 也实现了 MergedBeanDefinitionPostProcessor 接口的 postProcessMergedBeanDefinition 方法,它会在这个方法中寻找 @Autowired 注入点。CommonAnnotationBeanPostProcessor 也是基于此接口回调来实现的 @Resource 注入点的寻找,虽然这一步寻找到了注入点,但是并没有对属性或者方法进行注入,而只是保存起来了,在后面的流程中,会取出这些注入点,然后再进行注入。
addSingletonFactory
第三步:会判断当前是否允许解决循环依赖,如果允许的话会将创建好的 Bean 实例保证成功一个工厂方法,放入三级缓存,用来解决循环依赖的问题。
// 如果当前 bean 是单例,且允许循环依赖,并且这个 bean 正在创建中
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
if (earlySingletonExposure) {
if (logger.isTraceEnabled()) {
logger.trace("Eagerly caching bean '" + beanName +
"' to allow for resolving potential circular references");
}
// 那么将当前的 bean 对象保证成一个 lambda 工厂方法缓存到三级缓存,解决循环依赖的关键点
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
}那么为什么不直接将 Bean 实例直接放入三级缓存了,而要包装成一个工厂方法放入了,因为有可能这个 Bean 实例需要被 AOP,而此时按照正常流程是还没有进行 AOP 的,如果只是单纯的将一个 Bean 实例放入三级缓存,那么别的 Bean 依赖注入的会是一个原始对象,而非 AOP 的。而这个工厂方法做的事,就是判断你当前这个 Bean 是否需要 AOP,如果需要的话,就会进行 AOP 以后再把代理对象给你。
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
// 判断当前 bean 实例是否需求 AOP,如果需要 AOP,创建代理对象再返回给调用者
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (SmartInstantiationAwareBeanPostProcessor bp : getBeanPostProcessorCache().smartInstantiationAware) {
exposedObject = bp.getEarlyBeanReference(exposedObject, beanName);
}
}
return exposedObject;
}关于 Spring 的循环依赖就不详细展开了,可以看我的另一篇文章从源码角度分析Spring循环依赖
populateBean
第四步:首先回调所有 InstantiationAwareBeanPostProcessor 接口的 postProcessAfterInstantiation 方法,这个回调会将当前 Bean 对象和 beanName传递给你,此时的 Bean 对象还未进行属性注入。
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (InstantiationAwareBeanPostProcessor bp : getBeanPostProcessorCache().instantiationAware) {
if (!bp.postProcessAfterInstantiation(bw.getWrappedInstance(), beanName)) {
return;
}
}
}接着会去解析 BeanDefinition 的自动注入类型,总共有三种:
public enum Autowire {
/**
* 不自动注入
*/
NO(AutowireCapableBeanFactory.AUTOWIRE_NO),
/**
* 根据名字注入
*/
BY_NAME(AutowireCapableBeanFactory.AUTOWIRE_BY_NAME),
/**
* 根据类型注入
*/
BY_TYPE(AutowireCapableBeanFactory.AUTOWIRE_BY_TYPE);
}但是这种 byType 和 byName 已经不推荐使用,已经被设置为过时的了,所以一般默认值是 NO ,推荐使用 @Autowired 手动指定要注入的点。如果解析的 AutowireMode 是 byType 和 byName,那么就会按照你的自动注入类型进行依赖注入。然后就会对 InstantiationAwareBeanPostProcessor 接口的 postProcessProperties 方法进行回调,AutowiredAnnotationBeanPostProcessor 和 CommonAnnotationBeanPostProcessor 这两个 Bean 后置处理器都实现了这个方法,会在这里找到在第四步保准的注入点,进行依赖注入。
initializeBean
第五步:先执行 BeanNameAware BeanClassLoaderAware BeanFactoryAware
private void invokeAwareMethods(String beanName, Object bean) {
if (bean instanceof Aware) {
if (bean instanceof BeanNameAware) {
((BeanNameAware) bean).setBeanName(beanName);
}
if (bean instanceof BeanClassLoaderAware) {
ClassLoader bcl = getBeanClassLoader();
if (bcl != null) {
((BeanClassLoaderAware) bean).setBeanClassLoader(bcl);
}
}
if (bean instanceof BeanFactoryAware) {
((BeanFactoryAware) bean).setBeanFactory(AbstractAutowireCapableBeanFactory.this);
}
}
}然后回调所有的 BeanPostProcessor 接口的 postProcessBeforeInitialization 方法
public Object applyBeanPostProcessorsBeforeInitialization(Object existingBean, String beanName)
throws BeansException {
Object result = existingBean;
for (BeanPostProcessor processor : getBeanPostProcessors()) {
Object current = processor.postProcessBeforeInitialization(result, beanName);
if (current == null) {
return result;
}
result = current;
}
return result;
}接着执行实现了 InitializingBean 接口的 afterPropertiesSet 初始化回调方法,然后检查是否有设置 InitMethod 属性,有的话调用该方法。
接着执行 BeanPostProcessor 接口的 postProcessAfterInitialization 初始化后方法,AOP也是基于此实现的。
public Object applyBeanPostProcessorsAfterInitialization(Object existingBean, String beanName)
throws BeansException {
Object result = existingBean;
for (BeanPostProcessor processor : getBeanPostProcessors()) {
Object current = processor.postProcessAfterInitialization(result, beanName);
if (current == null) {
return result;
}
result = current;
}
return result;
}检查对象一致性
第六步:会从一二级缓存获取该 Bean 实例对象,如果获取到不为 null,说明发生了循环依赖,三级缓存被调用了,那么就会去判断经过第五步和第五步后的 exposedObject 和原始的 Bean 对象是否相等,如果不相等,说明在第四步和第五步产生了新的对象,但是在一二级缓存的对象已经被别人引用了,此时你又产生了一个新的对象,那么 Spring 就会抛出异常。
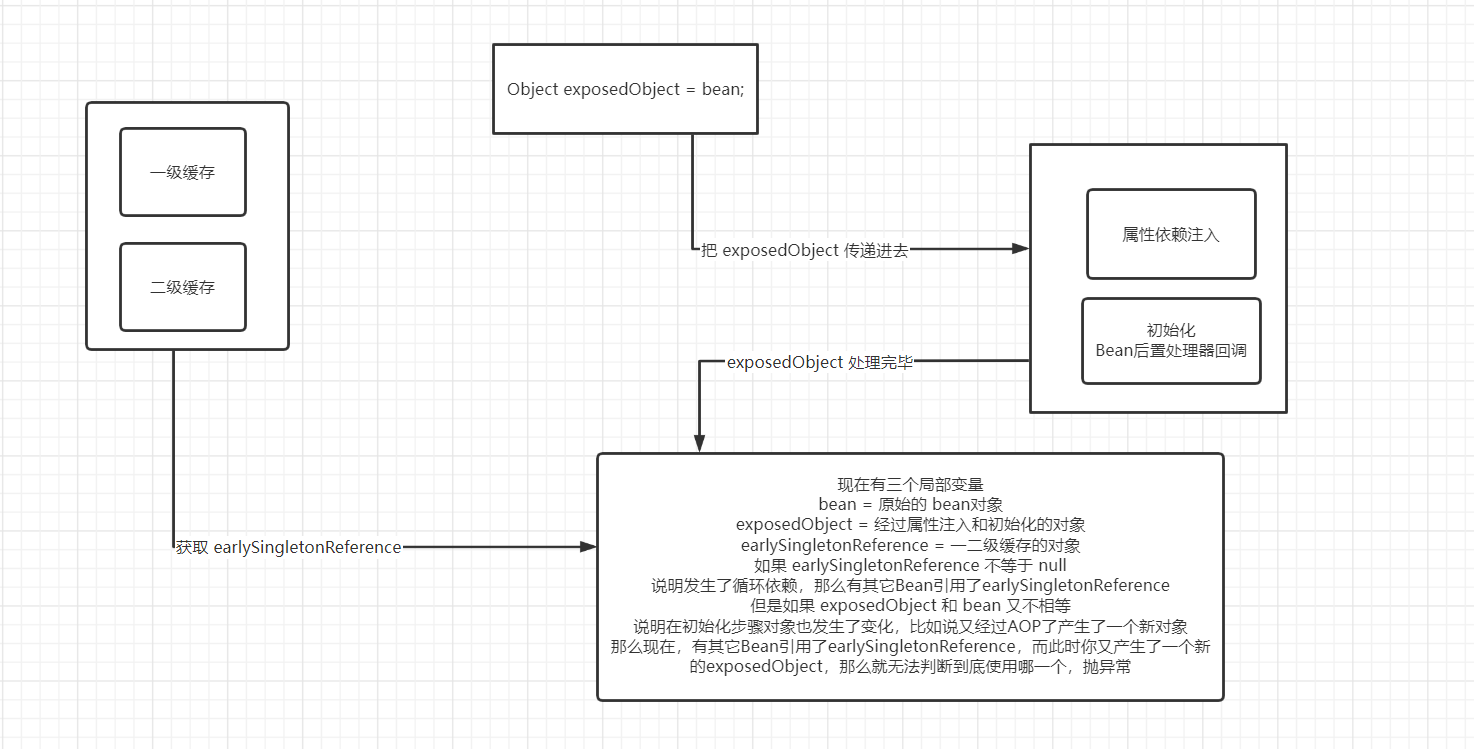
现在可以得出一个结论,如果你发生了循环依赖,就不能在初始化步骤产生一个新的对象,比方说 @Async 就会出现这样的问题,因为 @Async 是没有基于 AOP 进行动态代理的,而是自己创建了一个代理对象,比方说像下面这样的代码:com.demo7
@EnableAspectJAutoProxy
@EnableAsync
public class AppConfig {
}
public class BeanA {
@Autowired
private BeanB beanB;
@Async
public void test(){
System.out.println("异步方法");
}
}
public class BeanB {
@Autowired
private BeanA beanA;
}registerDisposableBeanIfNecessary
第七步:会将需要容器关闭需要进行回调的 Bean 使用适配器模式包装成一个 DisposableBeanAdapter 类型的类,然后注册到容器的 disposableBeans Map集合,当 Spring 容器关闭的时候,会对这个 Map 集合的所有 Bean 进行回调。那么什么样的 Bean 会被认为是需要进行关闭回调的。首先会将原型 Bean 排除在外,因为原型 Bean 并不会缓存在容器,主要判断以下几点任意一点符合就可以:
- 当前 Bean 是否实现了 DisposableBean 接口
- 当前 Bean 是否实现了 AutoCloseable 接口
- BeanDefinition 中是否指定了 destroyMethod
- 是否有 @PreDestroy 注解方法
总结
最后总结了一个 Bean 的创建流程图